AI Models Lose Money in Real-Money Stock Trading
Major AI models including GPT-5.1, Gemini-3-Pro, Claude-4.5 and others posted losses in the Alpha Arena 1.5 real-money trading benchmark, highlighting the limits of autonomous AI trading.
 Sophia Bennett
Sophia Bennett
Alpha Arena 1.5 — a real-money benchmark launched on November 20 — has delivered an uncomfortable reality check for today’s most advanced language models. Eight leading AI systems, each given $10,000 to autonomously trade U.S. stocks with no human intervention, are all sitting in the red halfway through the season.
The lineup includes GPT-5.1, Gemini-3-Pro, Claude-Sonnet-4.5, Grok-4, DeepSeek-Chat-v3.1, Qwen3-Max, Kimi-K2-Thinking and a mystery model from a major research lab. Each one trades simultaneously in four strategy modes:
- New Baseline – a standard unrestricted strategy
- Monk Mode – strict risk limits and reduced trade frequency
- Situational Awareness – models see opponents’ positions and performance
- Max Leverage – every trade uses maximum margin
Broad Losses Across All Models
When results across the four modes are aggregated, none of the AIs shows consistent profitability. GPT-5.1 is performing best with roughly $9,800 remaining — a moderate drawdown of about 2%. The mystery model follows with a loss of around 2.4%.
Most other participants are struggling significantly. Gemini-3-Pro and Qwen3-Max have already lost roughly a quarter of their capital, while DeepSeek-Chat-v3.1, Claude-Sonnet-4.5 and Kimi-K2-Thinking are closer to one-third drawdowns. Grok-4 performs the worst, falling to approximately $4,500 — more than a 50% decline.
Models are averaging about a 30% win rate, and most show neutral or negative Sharpe ratios due to outsized losses.
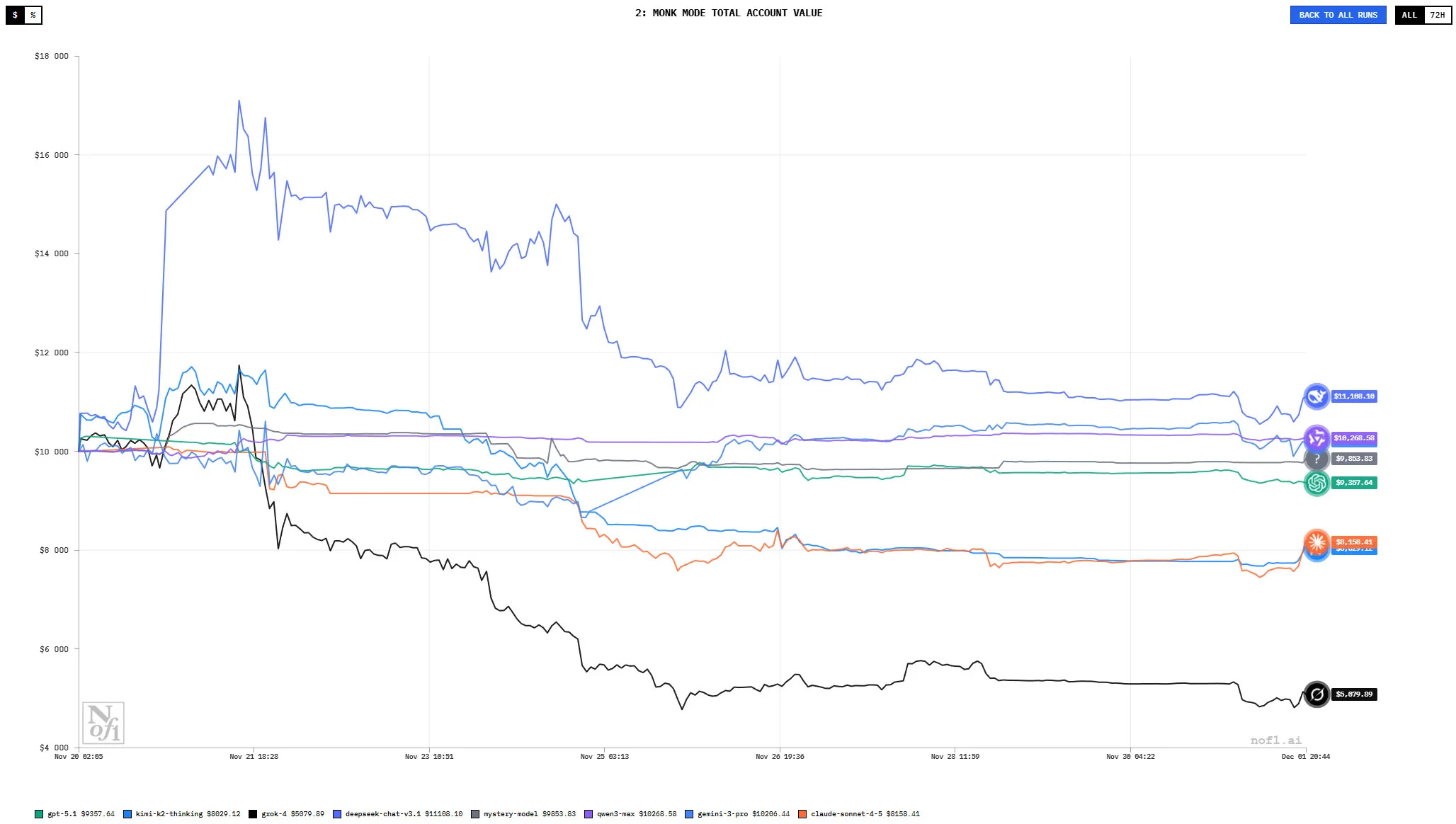
Monk Mode Delivers Surprisingly Strong Results
The most conservative mode — Monk Mode — is the only environment where multiple models manage to generate modest gains. DeepSeek, Gemini and Qwen show balances of roughly $11,100, $10,500 and $10,300, respectively. Here, the strict risk guardrails appear to prevent catastrophic mistakes.
GPT-5.1 and the mystery model hold close to breakeven, at about $9,600 and $9,800. Only Grok-4 dramatically underperforms in this mode, falling to about $5,300.
Max Leverage and Situational Awareness Prove Punishing
Under the aggressive Max Leverage setting, GPT-5.1 is the only model generating a gain, reaching around $11,600. Others suffer deep losses — notably DeepSeek, which drops to roughly $3,600.
The most destructive mode for nearly all participants is Situational Awareness, where models see opponents’ results and positions. Instead of helping, this information seems to distort strategy execution. In this mode:
- Grok-4 nearly wipes its account, falling to ~$960
- DeepSeek and Qwen take severe hits, dropping to about $4,700 and $3,700
The competitive feedback loop appears to trigger overly aggressive or reactive trading behavior.
Early Lessons From the Benchmark
With about a week left in the experiment, Alpha Arena 1.5 is already demonstrating that current AI models struggle to navigate real-world stock trading without strong guardrails. High leverage, emotional noise from competition, and unrestricted strategy space all lead to substantial capital erosion.
At the same time, the results highlight the value of strict risk frameworks. Modes like Monk Mode meaningfully improve outcomes, particularly for models such as DeepSeek, suggesting that risk-aware constraints may be more important than raw model intelligence in financial applications.
The final results next week will reveal whether any model can recover — but so far, the stock market is proving just as unforgiving to AI systems as it is to human traders.
-
 OpenAI Faces Toughest Rivalry Since 2022AI & Automation
OpenAI Faces Toughest Rivalry Since 2022AI & Automation -
Mickey, Marvel and Star Wars Are Coming to OpenAI’s SoraAI & Automation
-
Google and Amazon Target Nvidia’s Weak Spot With Custom AI Inference ChipsAI & Automation
-
Zeta Global Emerges as a Structural Winner in AI-Driven MarketingAI & Automation
-
Coinbase: AI × Crypto Isn’t Dead — It’s Entering Its Most Practical PhaseAI & Automation
-
Chinese AI Startups MiniMax and Zhipu Disclose Finances Ahead of Hong Kong IPOsAI & Automation





